SAM Audio - Meta推出的开源多模态音频分割模型
SAM Audio是Meta推出的开源多模态音频分割模型,从复杂的音频混合中精准分离出任意目标声音。通过结合文本、视觉和时间维度的提示,实现灵活、高效的音频处理,为音频编辑、去噪、声音提取等任务提供了全新解决方案。用户可以通过简单的文本描述(如“吉他声”)、在视频中点击发声物体,或者标记声音出现的时间范围来使用SAM Audio。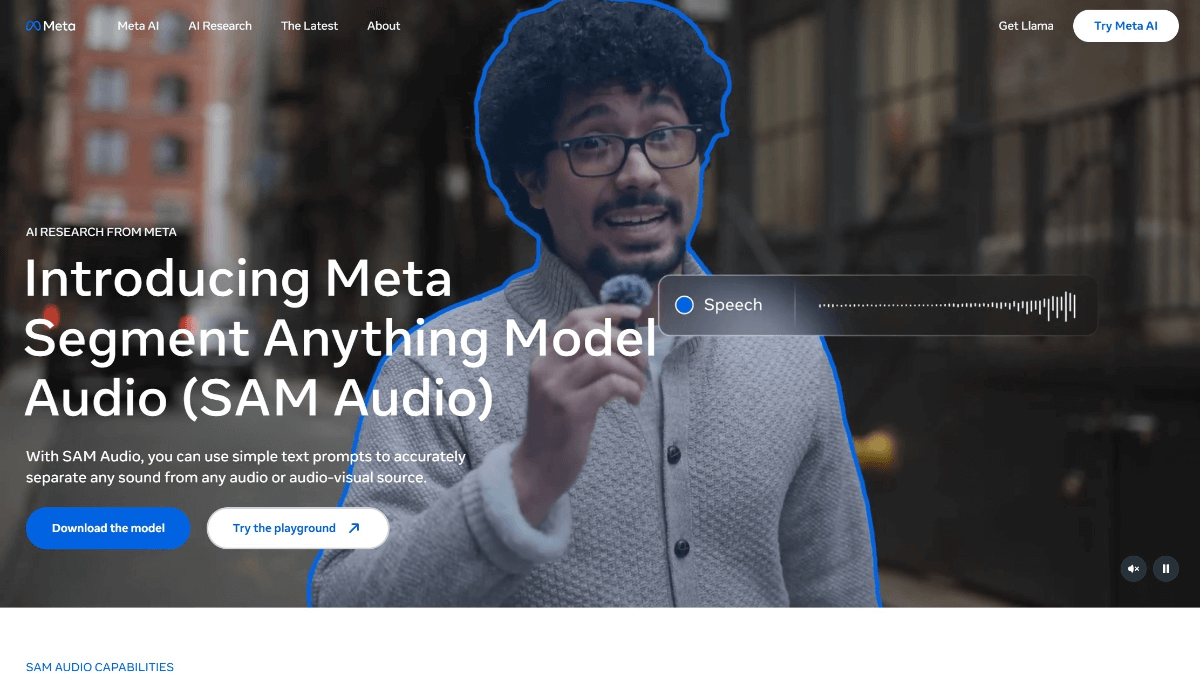
SAM Audio的功能特点
多模态提示支持:
文本提示:用户可通过自然语言描述(如“狗叫声”“人声”)提取对应声音。
视觉提示:在视频中点击发声对象(如乐器、说话者),自动分离其音频。
时间跨度提示:标记目标声音出现的时间段,实现精准定位分离。
统一模型架构:无需针对不同声音类别单独训练,可直接基于提示应用于新任务,具备较强的通用性和拓展性。
高性能与效率:在多种音频分离任务中超越现有模型,运行速度接近实时处理(实时因子约0.7),支持大规模音频处理。
应用场景广泛:适用于音频清理、背景噪声移除、音乐制作、视频后期处理、无障碍技术等领域,降低了专业音频处理的门槛。
SAM Audio的核心优势
多模态交互:支持文本、视觉和时间片段等多种提示方式,用户可以根据需求灵活选择,更贴近自然理解和处理音频的方式。
业界领先性能:在多种音频分离任务上实现领先性能,包括语音、音乐和通用音效分离,能够处理复杂音频混合。
无参考音频评测:配备SAM Audio Judge,提供无需参考音轨的客观音频质量评估,更贴近人类听觉体验。
高效实时处理:运行速度快于实时处理(实时因子约0.7),适合大规模音频处理,提升工作效率。
真实环境基准测试:通过SAM Audio-Bench进行评估,覆盖真实场景下的多种音频任务,确保模型在实际应用中的可靠性和有效性。
开源与社区支持:代码开源,便于开发者和研究人员进一步探索和应用,推动音频处理技术的发展。
SAM Audio官网是什么
项目官网:https://ai.meta.com/samaudio/
Github仓库:https://github.com/facebookresearch/sam-audio
SAM Audio的适用人群
音频编辑人员:需要清理音频、去除背景噪声或进行音频修复的专业音频编辑者。
创意媒体创作者:包括音乐制作人、视频编辑者和内容创作者,用于音频创意和重新混音。
研究人员:从事音频分析、声音生态学或音乐信息检索等领域的研究人员。
听力辅助设备开发者:与助听器制造商合作,为听力受损人群开发更有效的听力辅助技术。
普通用户:希望提升个人音频内容质量,或在日常生活中需要简单音频处理的用户。