Code2Video - Show Lab开源的AI教学视频生成框架
Code2Video是新加坡国立大学Show Lab团队创新的开源项目,能将代码片段自动转换为高质量的视频内容(mp4格式)。项目通过独特的代码中心范式,使用carbon-now-cli工具将代码生成精美的图片,利用ffmpeg将这些图片序列拼接成完整的教学视频。核心功能包括代码分割、图片生成、尺寸调整和视频合成四个主要组件,能模拟逐行输入代码的效果,特别适合制作编程教学和技术演示内容。
Code2Video是新加坡国立大学Show Lab团队创新的开源项目,能将代码片段自动转换为高质量的视频内容(mp4格式)。项目通过独特的代码中心范式,使用carbon-now-cli工具将代码生成精美的图片,利用ffmpeg将这些图片序列拼接成完整的教学视频。核心功能包括代码分割、图片生成、尺寸调整和视频合成四个主要组件,能模拟逐行输入代码的效果,特别适合制作编程教学和技术演示内容。
FireRedChat 是小红书开源的全双工语音交互系统,具有实时双向对话能力,支持可控打断功能。采用模块化设计,包括转录控制模块、交互模块和对话管理器等,支持级联和半级联架构,可灵活部署。系统基于 LiveKit RTC Server 实现实时通信,搭配 AI-Agent Bot Server 处理智能代理响应,通过 WebUI 提供用户交互界面。还配备 Redis Server 支持多节点托管,以及 TTS 和 ASR Server 分别处理语音合成和自动语音识别。
Logics-Parsing 是阿里开源的端到端文档解析模型,基于 Qwen2.5-VL-7B。通过强化学习优化文档布局分析和阅读顺序推断,能将 PDF 图像转换为结构化 HTML 输出,支持多种内容类型,包括普通文本、数学公式、表格、化学公式和手写中文字符。模型采用两阶段训练:第一阶段是监督微调,学习生成结构化输出;第二阶段是布局为中心的强化学习,优化文本准确性、布局定位和阅读顺序。在 LogicsParsingBench 基准测试中表现出色,尤其在纯文本、化学结构和手写内容解析方面优于其他方法。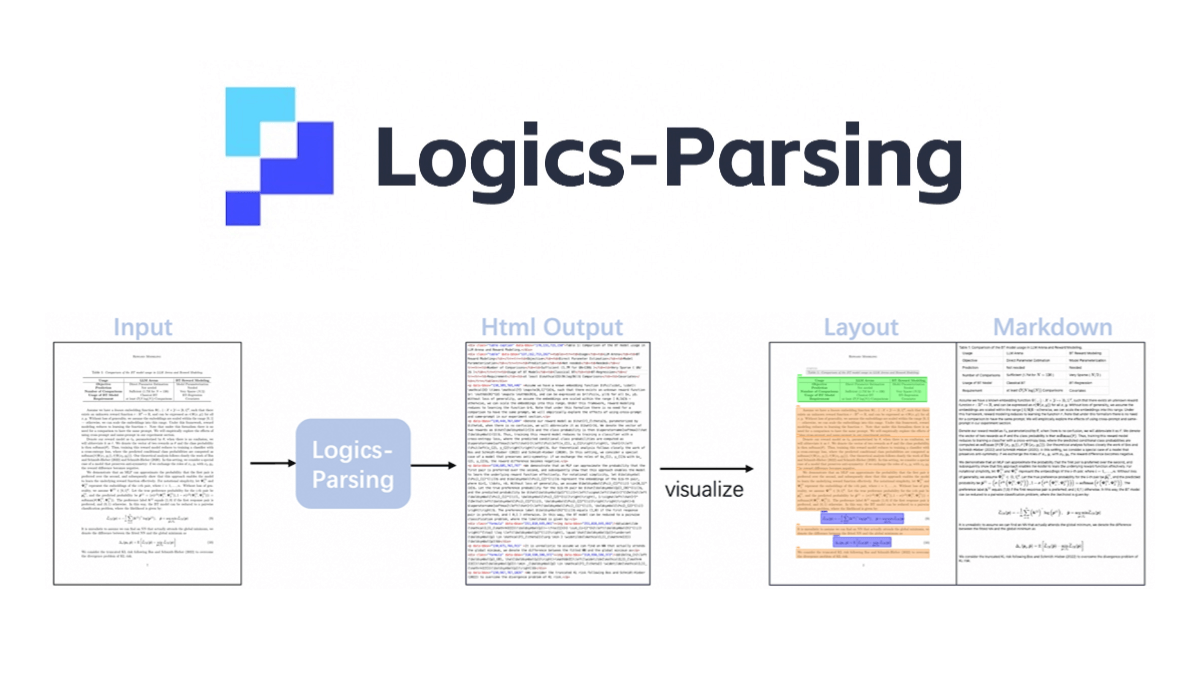
Grok 是 xAI 推出的大型语言模型,其 API 端点位于 https://api.x.ai。有时,我们可能希望通过自己的域名来访问这个 API,例如创建一个像 https://grokapi.yourdomain.com 这样的自定义端点。这可以通过设置 Nginx 反向代理来实现。本文将指导你完成这个过程。
Hunyuan3D-Part(混元3D-Part)是腾讯发布并开源的3D生成模型。由P3 - SAM和X - Part组成,首次实现高精度、可控的组件式3D生成,支持50 + 组件自动生成。用户可先用混元3D 2.5或3.0生成整体Mesh,再由P3 - SAM进行自动、精确的组件分割,X - Part将其分解为独立部件,输出高保真、结构一致的部件几何体,同时保持灵活可控性。混元3D - Part生成的模型精度高、可编辑、结构合理,让模型更易编辑、生产和应用。在游戏建模、3D打印等领域有广泛应用,如将汽车模型拆分车身和轮子,便于游戏绑定滚动逻辑或3D打印分步制作。代码和权重已开源,可通过c创作引擎免费使用。
HunyuanImage 3.0(混元图像3.0)是腾讯发布并开源的原生多模态图像生成模型。模型参数规模达80B,是目前测评效果最好、参数量最大的开源生图模型。混元图像3.0支持实时生图功能,用户可边打字边出图,毫秒级响应,超写实画质。支持复杂文本生成,如海报、漫画等,以及多种风格的图像生成,如实物摄影、科普插画等。具备原生多模态能力,可同时处理文字、图片、视频与音频等多种模态的输入与输出,无需多个模型组合。混元图像3.0拥有强大的语义理解与推理能力,能解析千字级别的复杂语义,生成长文本内容,可生成真实的高质感图片。
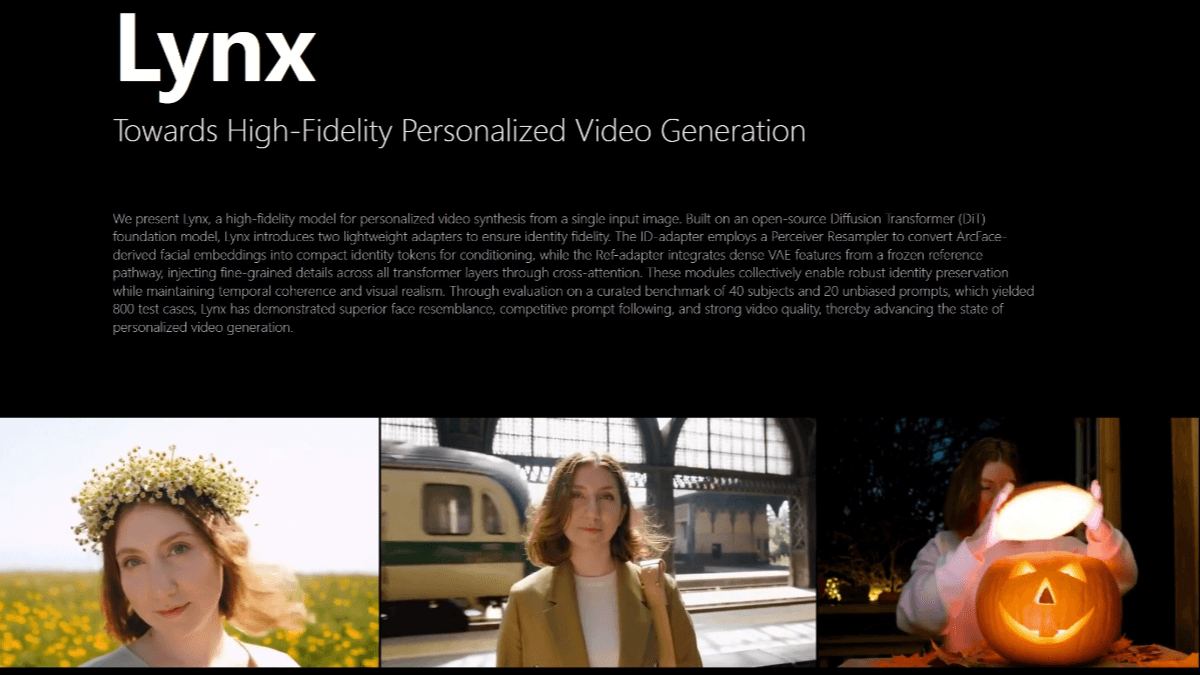
Lynx 是字节跳动开源的高保真个性化视频生成模型,仅需单张人像照片,能生成身份一致的视频。基于扩散 Transformer(DiT)基础模型构建,引入 ID-adapter 和 Ref-adapter 两个轻量级适配器模块,分别用于控制人物身份和保留面部细节。Lynx 采用人脸编码器捕捉面部特征,通过 X-Nemo 技术增强表情,LBM 算法模拟光影效果,确保人物身份在不同场景下的一致性。其交叉注意力适配器可将文本提示与人脸特征结合,生成符合场景要求的视频。Lynx 具备“时间感知器”,能理解动作物理规律,保持视频时间连贯性。在大规模测试中,Lynx 在面部相似度、场景匹配度和视频质量等多个维度上表现优异,超越同类技术。