gpt-realtime - OpenAI最新推出的AI语音模型
gpt-realtime 是 OpenAI 推出的先进语音模型,支持直接处理音频,生成自然流畅的语音。模型支持多种语言和风格,能理解非语言线索,如笑声,能在不同语言间切换。模型在指令遵循和功能调用方面表现出色,准确率显著提升。模型支持图像输入,借助 Realtime API,可基于图像内容展开对话。gpt-realtime 适用客服、教育、个人助理等多个领域,能有效提升效率和用户体验。
gpt-realtime 是 OpenAI 推出的先进语音模型,支持直接处理音频,生成自然流畅的语音。模型支持多种语言和风格,能理解非语言线索,如笑声,能在不同语言间切换。模型在指令遵循和功能调用方面表现出色,准确率显著提升。模型支持图像输入,借助 Realtime API,可基于图像内容展开对话。gpt-realtime 适用客服、教育、个人助理等多个领域,能有效提升效率和用户体验。
重新安装系统的方法有很多种,例如可以通过 U 盘、PE、微软官方的安装助手、又或者通过 Win11 重置此电脑等等。系统的重装本来就是简单而免费的事情。新手小白如何简单免费又快速的重新安装系统呢?今天给大家介绍「reinstall」这个开源项目,只需要一条命令就可以重装系统,并且支持 Windows 和 Linux 的系统重装。
Youtu-agent 是腾讯优图实验室开源的智能体框架,用在构建和运行自主智能体。框架在 WebWalkerQA 和 GAIA 基准测试中表现出色,准确率分别达到 71.47% 和 72.8%。框架开源友好,不依赖闭源模型,适合多种应用场景。Youtu-agent支持多种任务,如 CSV 分析、文献综述和文件组织等。基于 YAML 的配置和自动化设置,简化智能体的生成和部署。Youtu-agent 支持多种模型 API 和工具集成,具有灵活的架构,可广泛应用在数据分析、文件管理、内容生成等领域。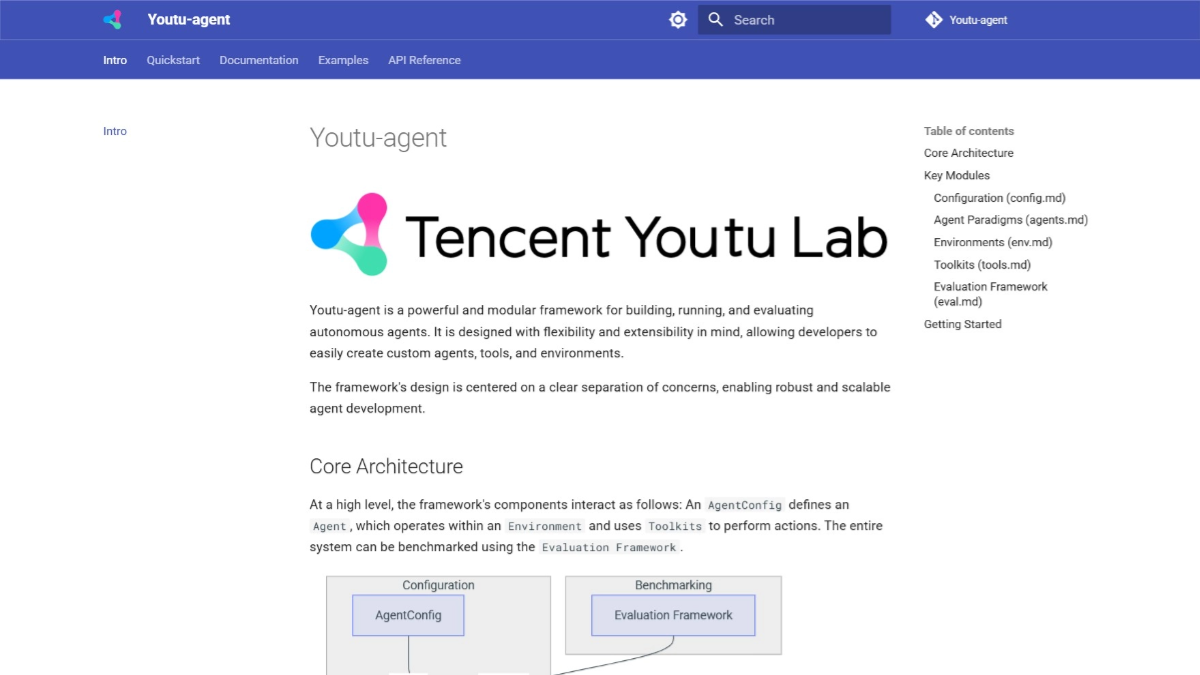
HunyuanVideo-Foley 是腾讯混元团队开源的视频音效生成模型,支持为无声视频添加精准匹配的音效。模型基于大规模数据集训练,用多模态扩散变换器架构,结合表征对齐损失函数和音频VAE优化技术,能生成高质量、层次丰富的音效。模型适用短视频创作、电影制作、广告创意、游戏开发等场景,能显著提升内容的沉浸感和吸引力,让创作更高效、更专业。
MiniCPM-V 4.5 是面壁智能开源的 8B 参数多模态模型,基于 Qwen3-8B 和 SigLIP2-400M 构建,具备高效处理图像和视频的能力。在视觉 Token 消耗上表现出色,处理 180 万像素图像仅需 640 个视觉 Token,大大减少了计算资源消耗。模型在高刷视频理解方面表现突出,可接收 6 倍视频帧数量,达到 96 倍视觉压缩率,是同类模型的 12-24 倍。MiniCPM-V 4.5 支持多语言交互,可处理 30 多种语言,适用于多语言客服和翻译场景。文档处理能力也非常出色,能处理复杂图表和票据,支持手写体 OCR 和多语言文档解析。模型支持长思考和短思考的可控混合推理,可根据实际需求灵活调整推理速度和深度。
Gemini 2.5 Flash Image(代号nano banana)是谷歌推出的先进图像生成与编辑模型,能保持角色在不同场景中的一致性,支持通过自然语言进行精准图像编辑,如模糊背景、消除污渍等。模型结合 Gemini 的世界知识,能理解手绘图表并执行复杂指令。用户能通过 Google AI Studio 、Gemini API等平台使用模型,模型生成的图片带有隐形数字水印,便于识别 AI 创作内容。Gemini 2.5 Flash Image 为创意设计、广告营销、影视动画等领域带来强大的功能体验。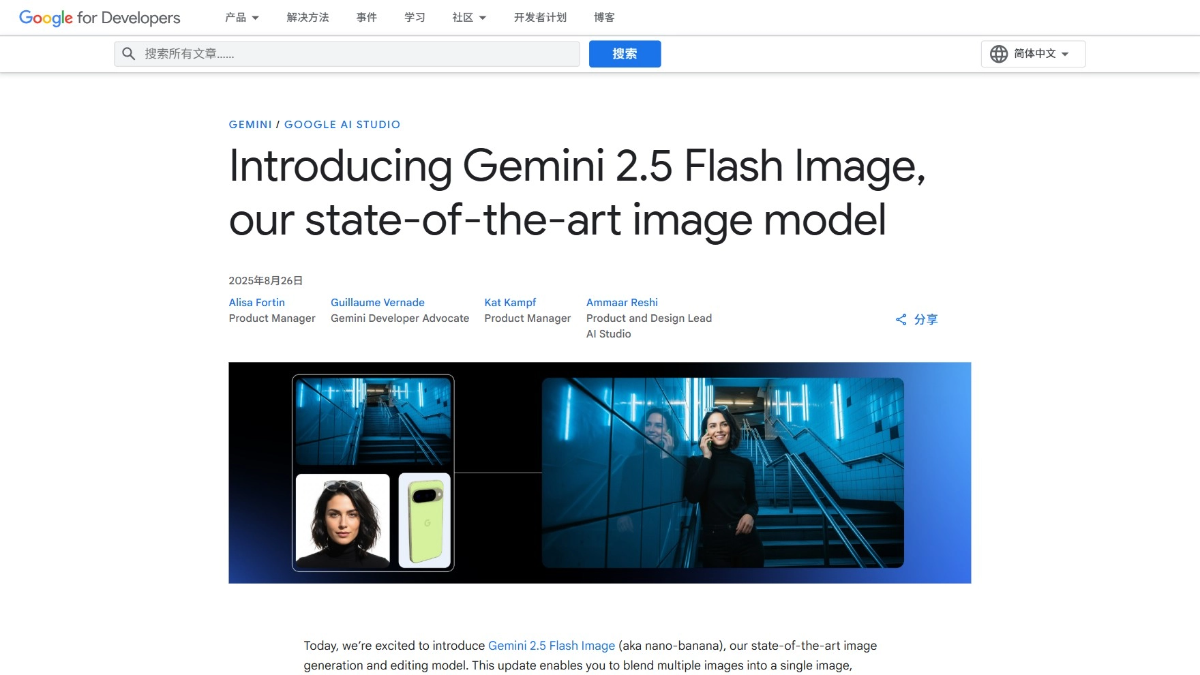
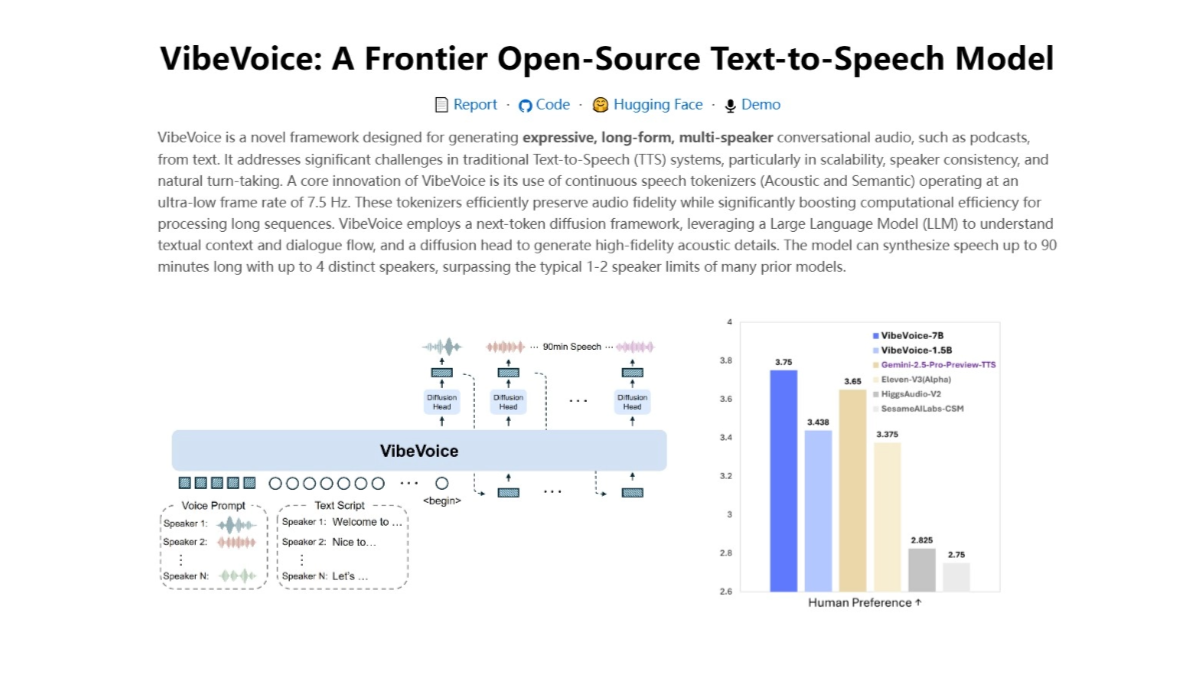
VibeVoice 是微软推出的新型文本到语音(TTS)模型。模型能生成多达 4 位不同说话者的对话式音频,支持长达 90 分钟的连续语音输出,突破传统 TTS 系统的长度限制。VibeVoice 生成的语音富有表现力,能根据文本内容产生带有情感和语调的语音,让对话更自然生动。VibeVoice支持多种语言的语音合成,能处理跨语言对话场景,生成的语音质量高,接近人类自然语音。VibeVoice 能应用在播客制作、有声读物、虚拟助手、教育和培训、娱乐和游戏等多个领域,为相关场景提供自然流畅的语音交互体验。