DINOv3 - Meta AI推出的新一代自监督视觉基础模型
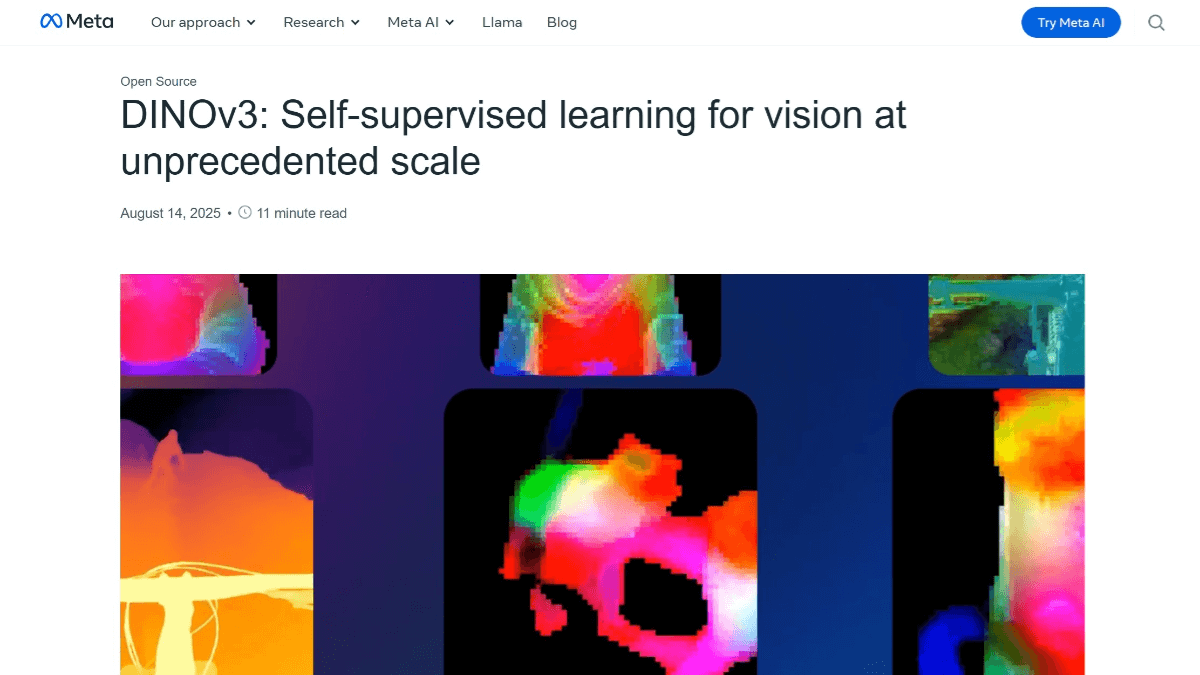
DINOv3 是 Meta AI 推出的新一代自监督视觉基础模型,采用自监督学习范式,无需标注数据即可学习图像特征。通过改进数据准备和引入 Gram anchoring 解决了特征退化问题,提升了泛化能力。DINOv3 提供 ViT 和 ConvNeXt 两种骨干网络架构,其中 ViT-7B 是目前规模最大的版本,包含 67 亿参数。模型能生成高质量的密集特征表示,精准捕捉图像的局部关系和空间信息。在图像分类、目标检测、语义分割等多种视觉任务中表现出色,无需任务特定微调即可超越许多专业模型。DINOv3 支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景。