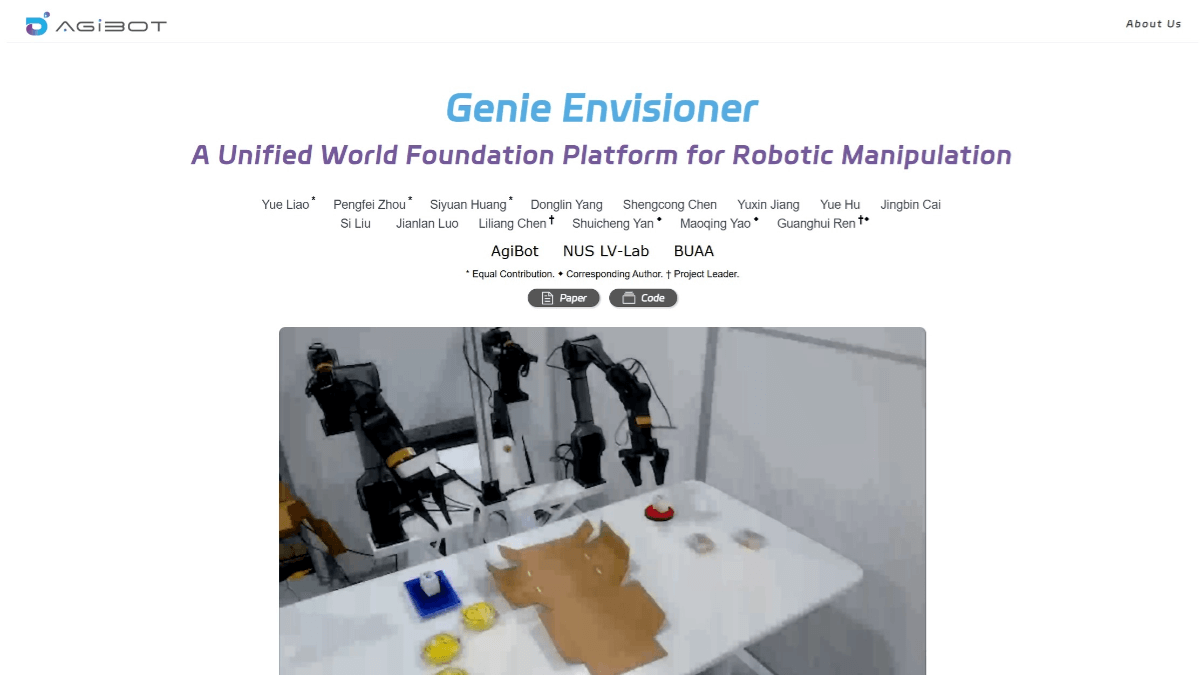
Genie Envisioner(GE)是智元机器人团队联合新加坡国立大学、北京航空航天大学等机构开发的机器人操作统一平台。通过“先想象,后行动”的方式,让机器人更好地理解和执行任务。GE的核心包括三个部分:GE-Base、GE-Act和GE-Sim。GE-Base是一个指令驱动的视频扩散模型,能捕捉机器人在真实世界中的交互动态。GE-Act基于GE-Base,将潜在的表示转化为可执行的动作轨迹,支持不同形态的机器人。GE-Sim是一个动作条件的神经模拟器,能生成高保真的模拟视频,用于训练和评估。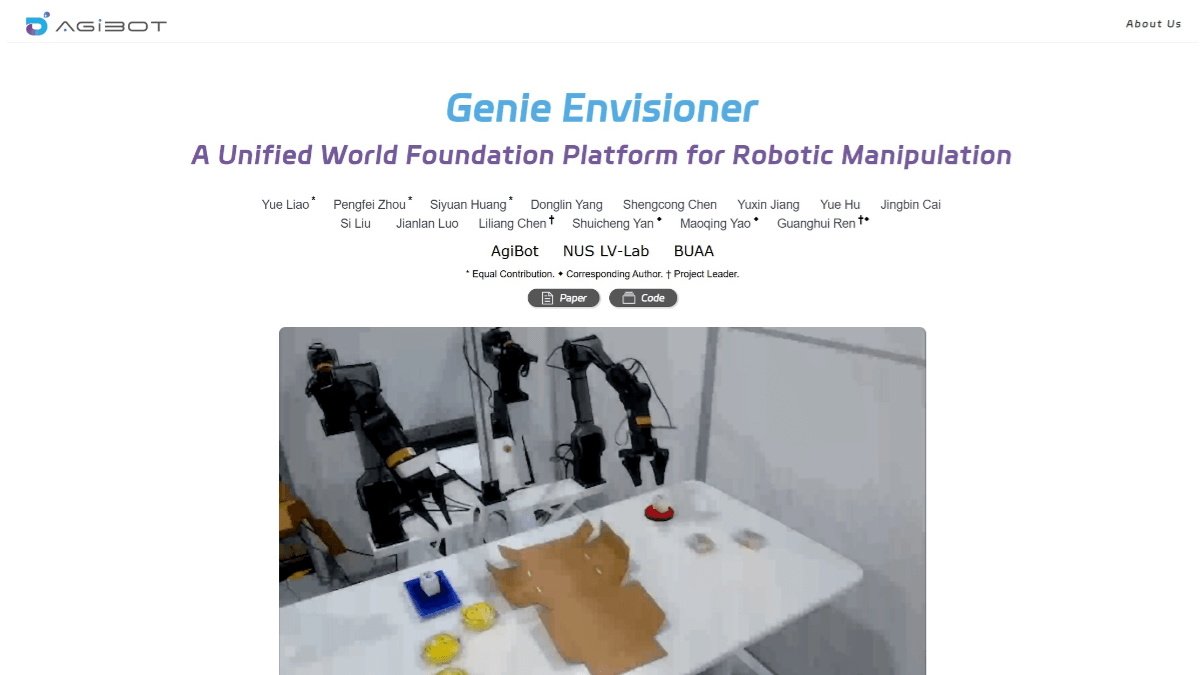
>>展开阅读
Mureka V7.5 是昆仑万维推出的先进 AI 音乐生成模型,专注于中文歌曲创作。模型能精准还原音色与演奏技法,生成自然流畅且富有情感的歌声。基于优化的自动语音识别(ASR)技术,Mureka V7.5 支持分析真实演唱中的细节,精准识别唱词并捕捉情感起伏,生成更自然的人声。Mureka V7.5 能深度理解中文音乐的文化背景和艺术神韵,支持从传统民歌到流行金曲等多种风格。Mureka V7.5 能为音乐人提供高效创作工具,为影视、游戏、虚拟角色等提供定制化音乐,拓展音乐创作的边界。
>>展开阅读
Hunyuan-GameCraft 是腾讯 Hunyuan 团队开源的交互式游戏视频生成框架。框架能从单张图片和提示生成高动态的游戏视频,支持用户通过键盘和鼠标实时控制视频内容。框架将输入统一到共享的相机表示空间,实现精细的动作控制,同时用混合历史条件训练策略,确保视频的长期连贯性。借助模型蒸馏技术,显著提高推理速度,适合实时部署。Hunyuan-GameCraft在超过100款AAA游戏的海量数据上训练,生成的视频具有高视觉保真度和真实感,广泛应用在游戏视频生成、游戏测试、内容扩展及互动视频创作等领域。
>>展开阅读
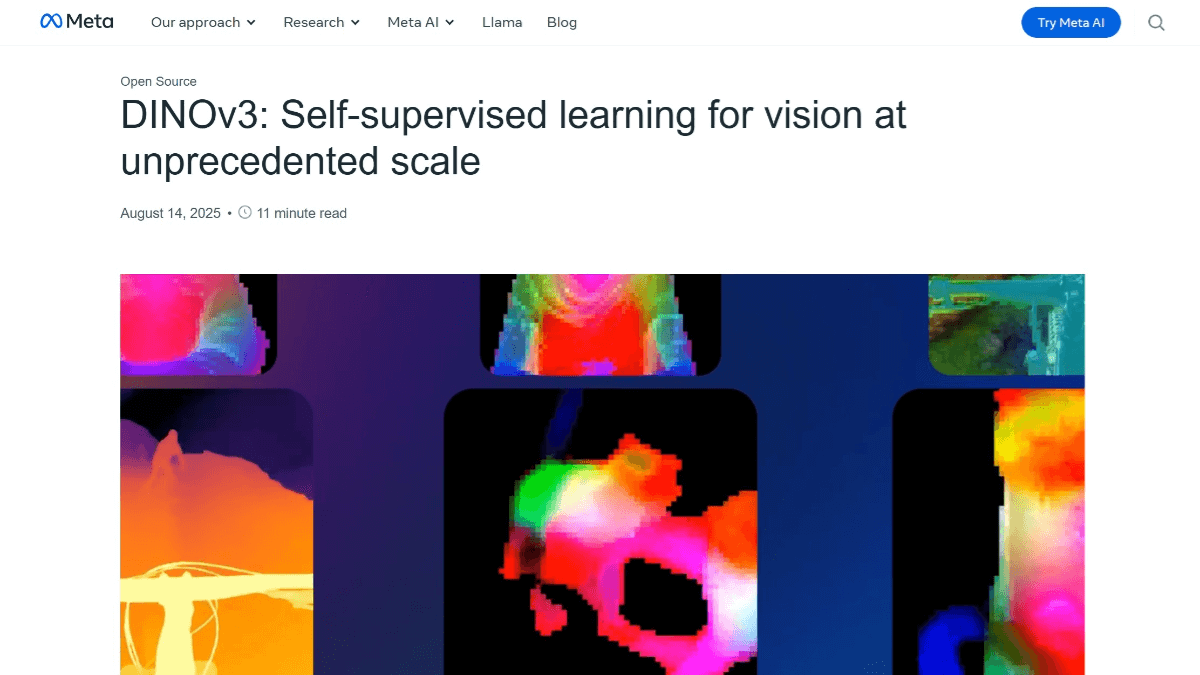
DINOv3 是 Meta AI 推出的新一代自监督视觉基础模型,采用自监督学习范式,无需标注数据即可学习图像特征。通过改进数据准备和引入 Gram anchoring 解决了特征退化问题,提升了泛化能力。DINOv3 提供 ViT 和 ConvNeXt 两种骨干网络架构,其中 ViT-7B 是目前规模最大的版本,包含 67 亿参数。模型能生成高质量的密集特征表示,精准捕捉图像的局部关系和空间信息。在图像分类、目标检测、语义分割等多种视觉任务中表现出色,无需任务特定微调即可超越许多专业模型。DINOv3 支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景。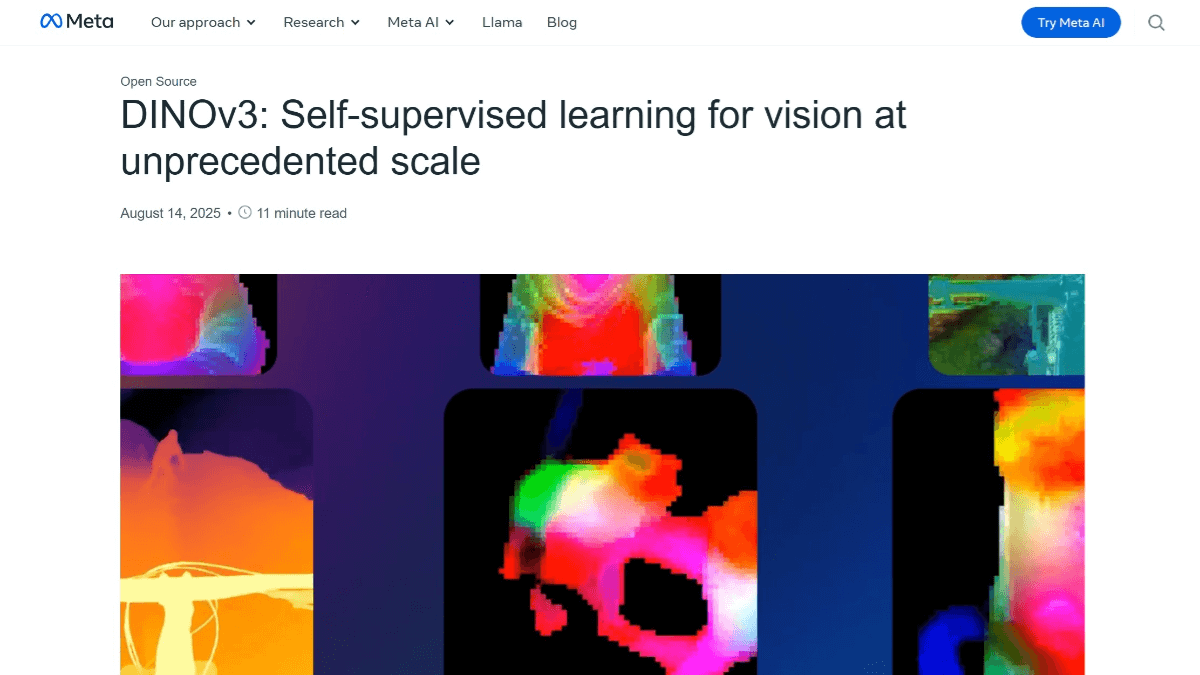
>>展开阅读
Genie Envisioner(GE)是智元机器人团队联合新加坡国立大学、北京航空航天大学等机构开发的机器人操作统一平台。通过“先想象,后行动”的方式,让机器人更好地理解和执行任务。GE的核心包括三个部分:GE-Base、GE-Act和GE-Sim。GE-Base是一个指令驱动的视频扩散模型,能捕捉机器人在真实世界中的交互动态。GE-Act基于GE-Base,将潜在的表示转化为可执行的动作轨迹,支持不同形态的机器人。GE-Sim是一个动作条件的神经模拟器,能生成高保真的模拟视频,用于训练和评估。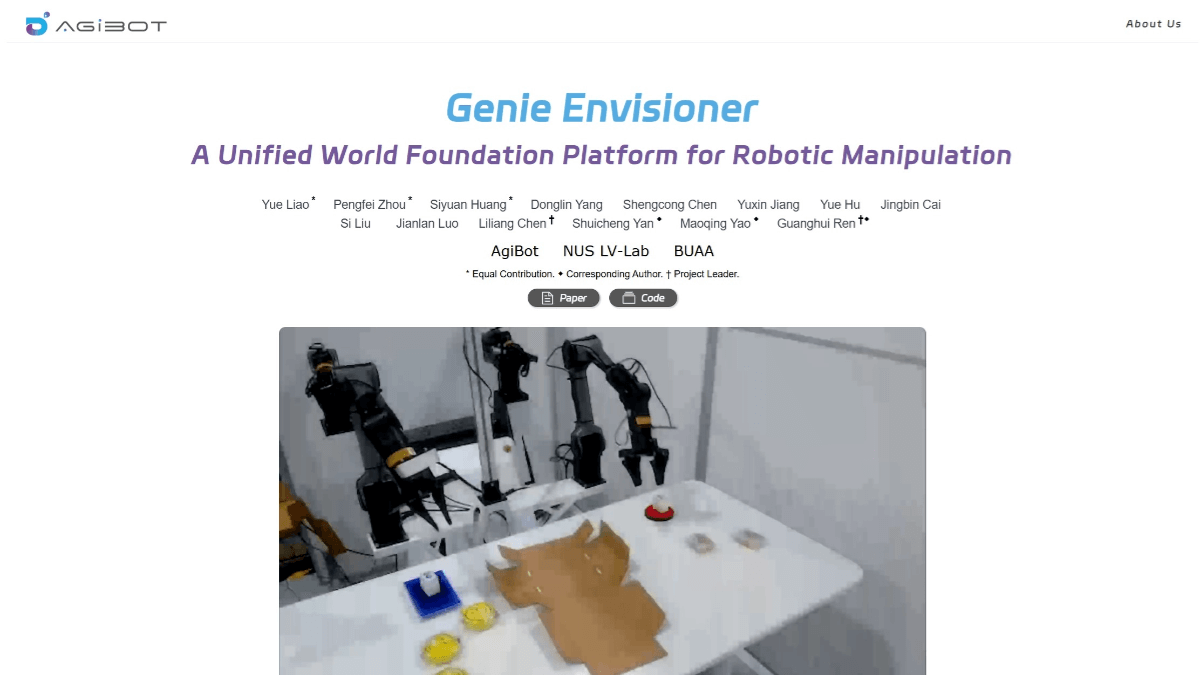
>>展开阅读
RynnRCP 是阿里达摩院开源的机器人上下文协议,能降低具身智能开发门槛并打通开发全流程。RynnRCP 包含 RCP 框架和 RobotMotion 模块。RCP 框架通过能力抽象和多协议支持,将复杂硬件接口封装为标准化服务接口,实现机器人与云平台、边缘设备的高效通信。RobotMotion 模块将低频推理命令转换为高频控制信号,确保机器人运动平滑连贯,并提供仿真、调试、数据采集等功能。RynnRCP 适用工业自动化、物流仓储、服务机器人、医疗康复、农业与环境监测等场景,助力开发者快速实现机器人应用开发。
>>展开阅读
RynnEC是阿里巴巴达摩院推出的世界理解模型,专注于具身智能任务。模型基于多模态融合技术,结合视频数据和自然语言,能从多个维度解析场景中的物体,支持物体理解、空间感知和视频目标分割等功能。RynnEC无需依赖3D模型,仅靠视频序列就能建立连续的空间感知,能根据自然语言指令完成任务。模型在家庭服务机器人、工业自动化、智能安防、医疗辅助和教育培训等多个领域有广泛应用,为机器人和智能系统提供强大的语义理解能力,助力其更好地理解物理世界。
>>展开阅读
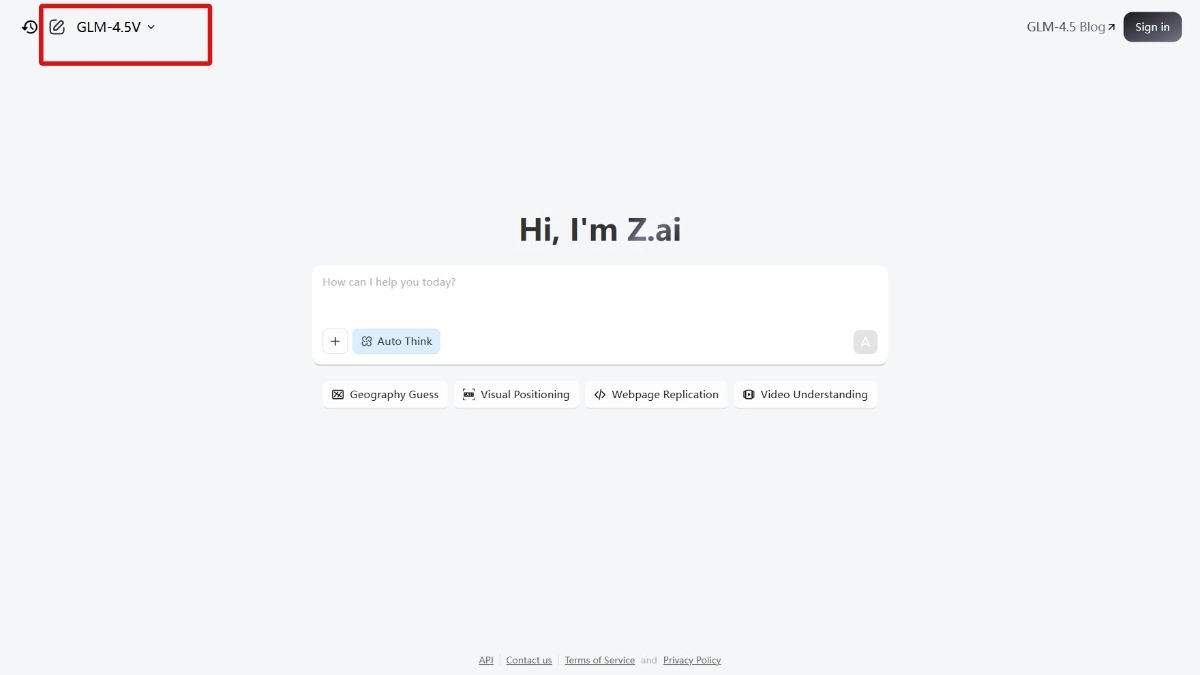
GLM-4.5V是智谱推出的全球领先的开源视觉推理模型,总参数达1060亿,激活参数120亿。模型基于新一代文本基座模型GLM-4.5-Air训练而成,具备强大的视觉理解与推理能力,能处理图像、视频、文档等多种视觉内容。模型在多模态任务中表现出色,涵盖视觉问答、图像描述生成、视频理解、网页前端复刻等场景,同时支持快速响应与深度推理的灵活切换。GLM-4.5V在41个公开视觉多模态榜单中达到SOTA性能,通过高效混合训练实现全场景视觉推理,为企业和开发者提供高性价比的多模态AI解决方案。
>>展开阅读
- «
- 1
- ...
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- ...
- 20
- »