LongCat-Flash-Omni 是美团 LongCat 团队发布的开源全模态大语言模型。拥有5600亿参数规模(激活参数270亿),在保持庞大参数量的同时,实现了毫秒级的实时音视频交互能力。模型基于 LongCat-Flash 系列的高效架构设计,创新性地集成了多模态感知模块与语音重建模块,支持文本、图像、视频理解及语音感知与生成等多种模态任务。LongCat-Flash-Omni 在全模态基准测试中达到开源最先进水平(SOTA),在文本、图像、音频、视频等关键单模态任务中均展现出极强的竞争力。采用渐进式早期多模融合训练策略,逐步融入不同模态数据,确保全模态性能强劲且无单模态性能退化。模型支持128K tokens上下文窗口及超8分钟音视频交互,具备多模态长时记忆和多轮对话能力。
>>展开阅读
我们痴迷于“思考机器”的崛起,却忽视了“思考人群”的加速衰退。这种“自我缴械”,正让深度思考力提前消亡,此消彼长才是真正的危机。文章来自编译。
>>展开阅读
马斯克关于人工智能如何重塑人类文明的宏大愿景,不仅仅是技术升级。他详细阐述了三个核心基础设施:Grok,作为一个能理解意图并执行任务的行动系统,将取代传统的搜索模式;交互方式的革命,即在未来五年内,手机将取消应用程序和操作系统,只保留屏幕和语音功能,以对话形式驱动一切行动;以及Optimus机器人,作为AI进入物理世界的载体,负责执行体力劳动。马斯克认为,这套系统最终将创造一个物质富足的社会,工作不再是生存手段,而是个人选择,并强调确保AI追求最大限度的真相以保障人类安全的重要性。
>>展开阅读
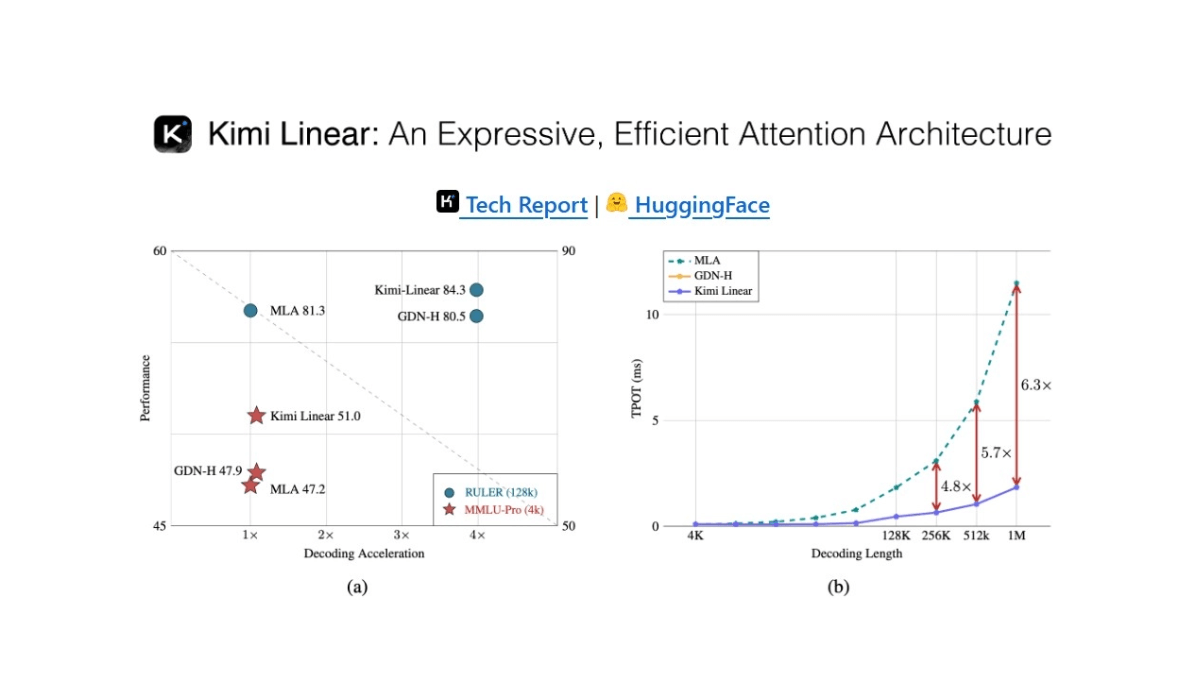
Kimi Linear 是月之暗面开源的新型混合线性注意力架构,以 Kimi Delta Attention(KDA)为核心,通过更细粒度的门控机制优化了传统注意力模型,显著提升了硬件效率和内存控制能力。架构采用 3:1 的混合层级结构,即每三个 KDA 线性注意力层后插入一个全注意力层(MLA),既保证了高效的局部信息处理,又能周期性地捕捉全局依赖关系。结合专家混合(MoE)技术,Kimi Linear 在 480 亿参数规模下,每个前向传播仅激活 30 亿参数,大幅提升了计算效率。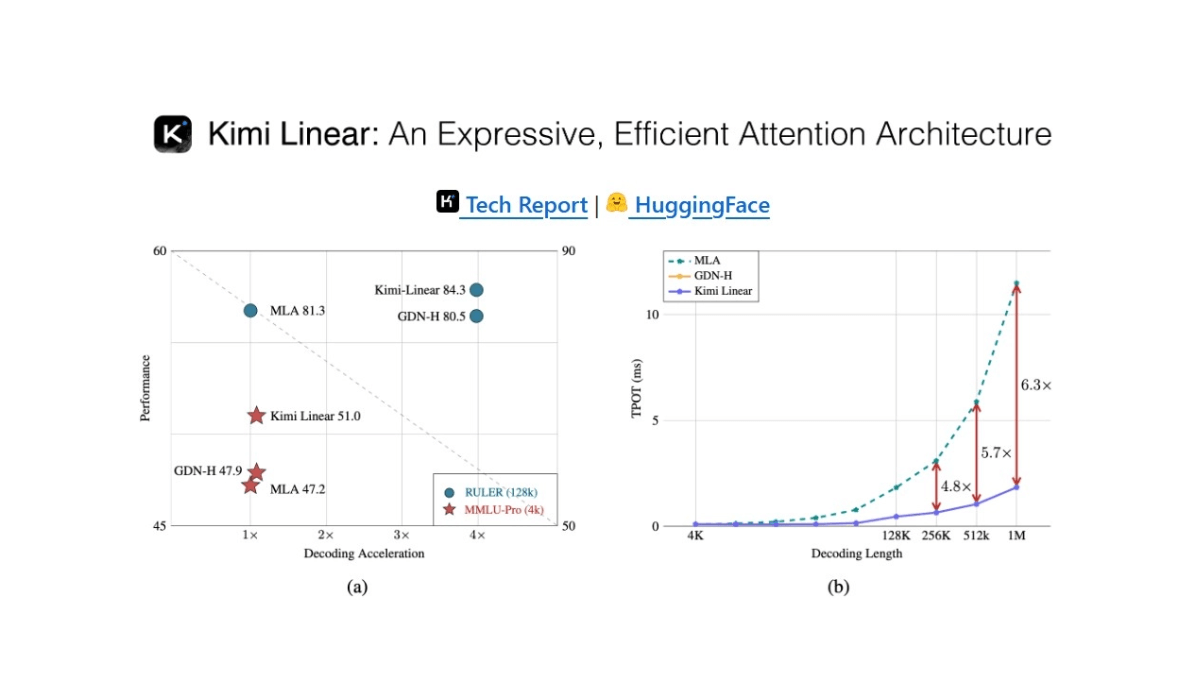
>>展开阅读
FIBO 是 Bria AI 开发的全球首个开源的原生支持 JSON 的文本生成图像模型。基于 8B 参数的 DiT(扩散 Transformer)架构,采用流匹配(Flow Matching)训练方式,使用 SmolLM3-3B 作为文本编码器,并在超过 1 亿条结构化 JSON 描述上训练而成。FIBO 的核心优势在于其 VLM 引导的 JSON 原生提示词体系,能将简短的文本提示扩展为详细的结构化描述,生成高质量的图像。支持迭代可控生成,用户可以基于已有 JSON 或图像进行多轮细化与灵感扩展,能单独调整某个属性而不破坏整体场景。FIBO 提供 API 接口、ComfyUI 节点及本地推理支持,便于开发者集成和使用。FIBO 100% 使用授权数据,确保了企业级的合规性。
>>展开阅读
利用 AI 来智能化的方式自动记录、分析和总结您的日常屏幕活动免费开源工具「Screen Analyzer」据介绍基于 Tauri + Vue 3 + Rust 开发的跨平台桌面应用,支持主流的 LLM API 配置。
>>展开阅读
免费 AI 图像生成工具「Freeaiimage」免费用户目前每天有 30 张图像配额,几秒钟内将文本转换为图像,编辑、增强和优化照片。据介绍基于 Flux Schnell 免费 AI 图像生成器的能力。
>>展开阅读
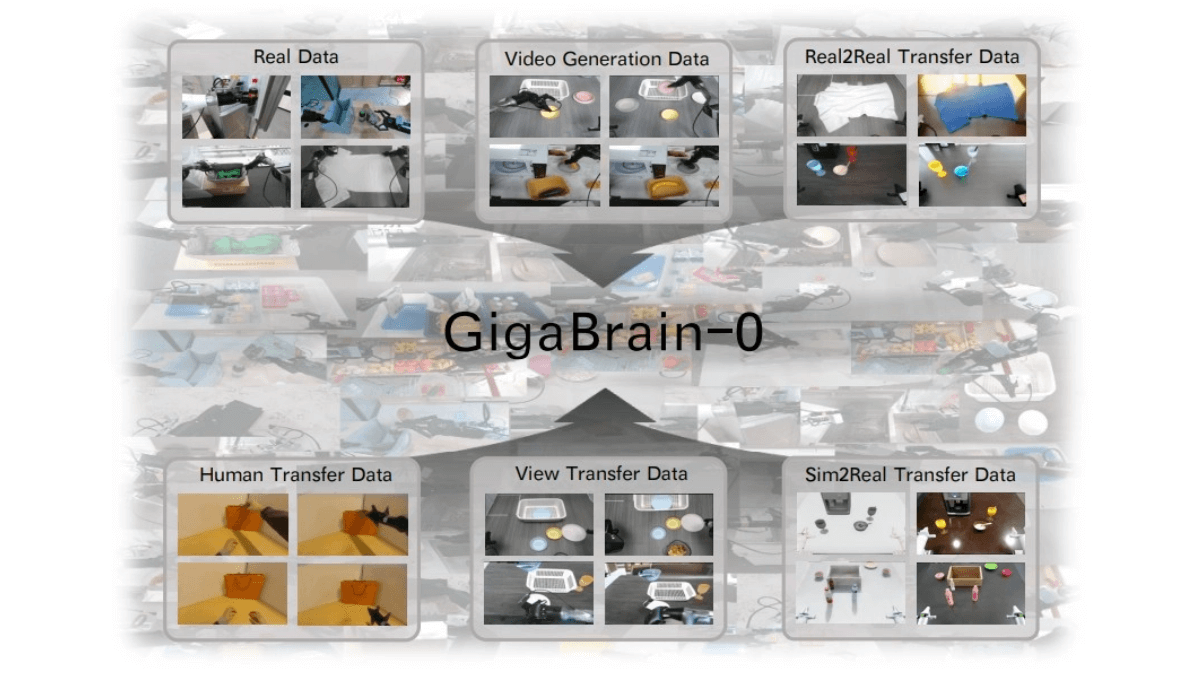
GigaBrain-0是国内首个利用世界模型生成数据实现真机泛化的端到端视觉-语言-动作(VLA)具身基础模型,由极佳视界与湖北人形机器人创新中心联合发布开源。采用混合Transformer架构,融合预训练视觉语言模型(VL-M)与动作扩散Transformer(DIT),支持RGB-D输入,增强3D空间感知能力。引入“具身思维链(Embodied CoT)”机制,生成中间推理步骤(如操作轨迹、子目标语言),提升长时程任务规划能力。以“世界模型”为核心构建数据引擎,通过仿真生成、风格迁移、视角变换等技术,生成多样化训练数据,减少对真实世界数据的依赖。数据覆盖工业、商业、办公、家居等多场景,提升模型泛化能力。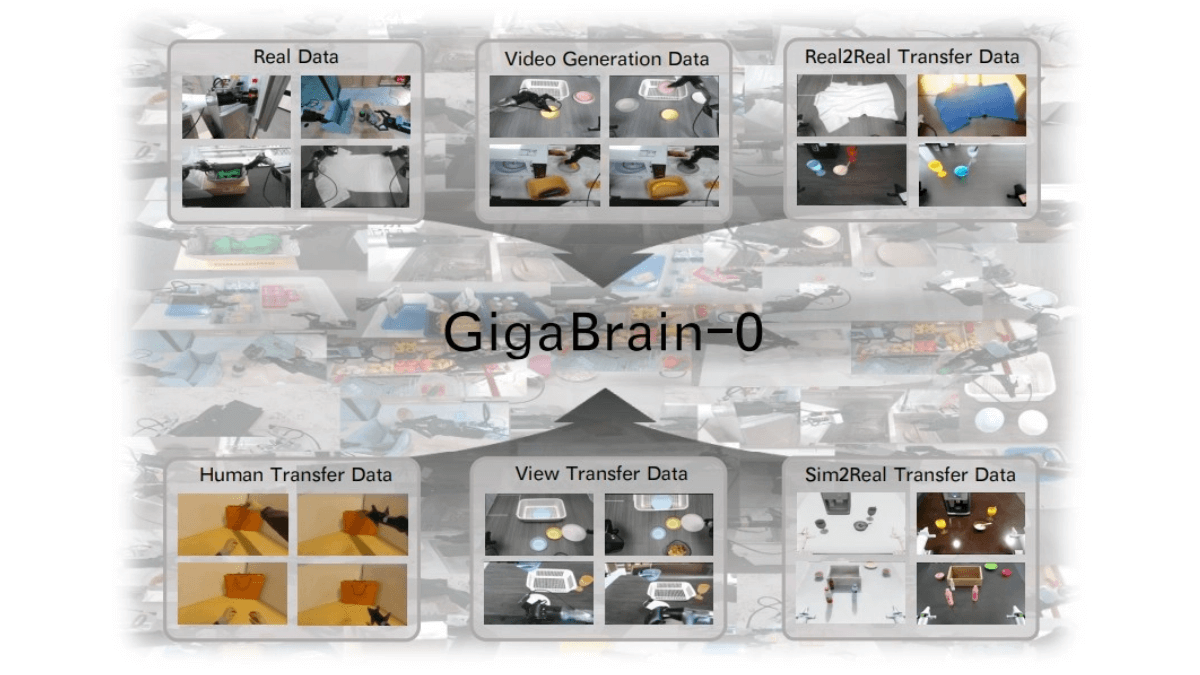
>>展开阅读
- «
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- ...
- 20
- »