FG-CLIP 2 - 360开源的图文跨模态视觉语言模型
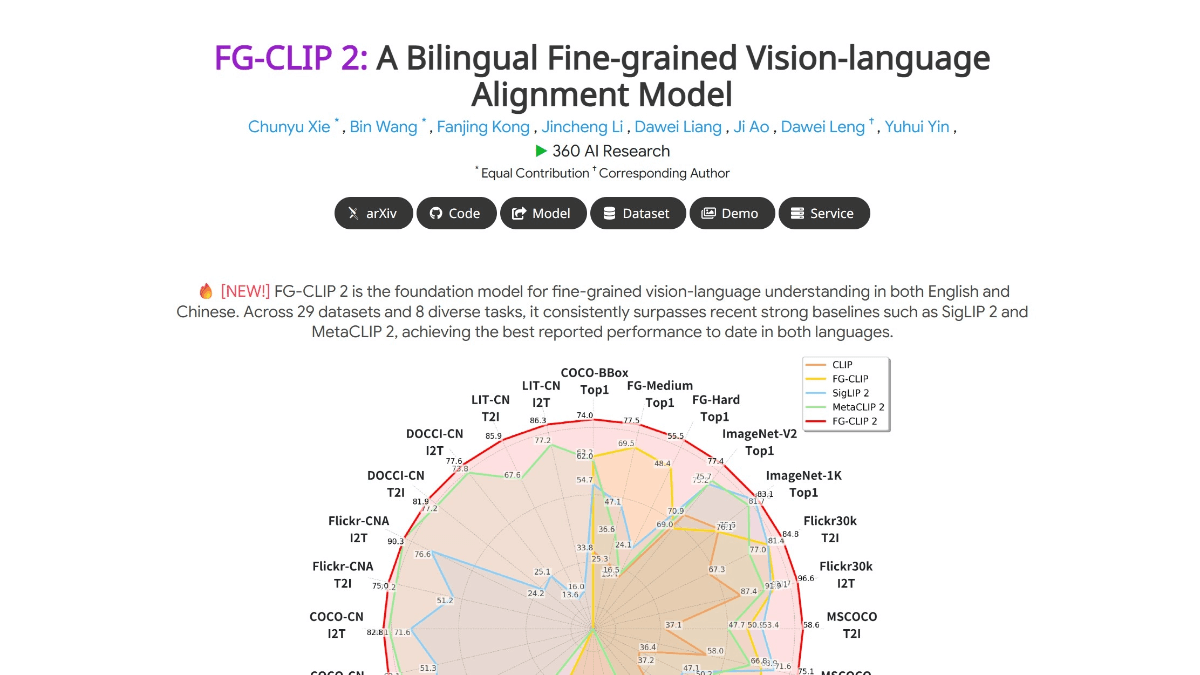
FG-CLIP 2 是360人工智能研究院推出的全球领先的图文跨模态视觉语言模型(VL-M),在29项权威基准测试中超越Google和Meta的同类模型,成为目前性能最强的VL-M。能精准识别图像中的毛发、斑点、色彩、表情、空间关系等细节,例如区分不同品种的猫、判断物体在屏幕内外的位置,甚至理解复杂场景中的遮挡关系。同时支持中文和英文的细粒度理解,填补了中文跨模态模型的空白,可精准处理中文长文本检索、区域分类等任务。采用两阶段训练策略,先全局对齐图文语义,再聚焦局部细节对齐;结合五维协同优化体系,提升模型的抗干扰性和鲁棒性。