Klear-Reasoner - 快手推出的全新推理模型
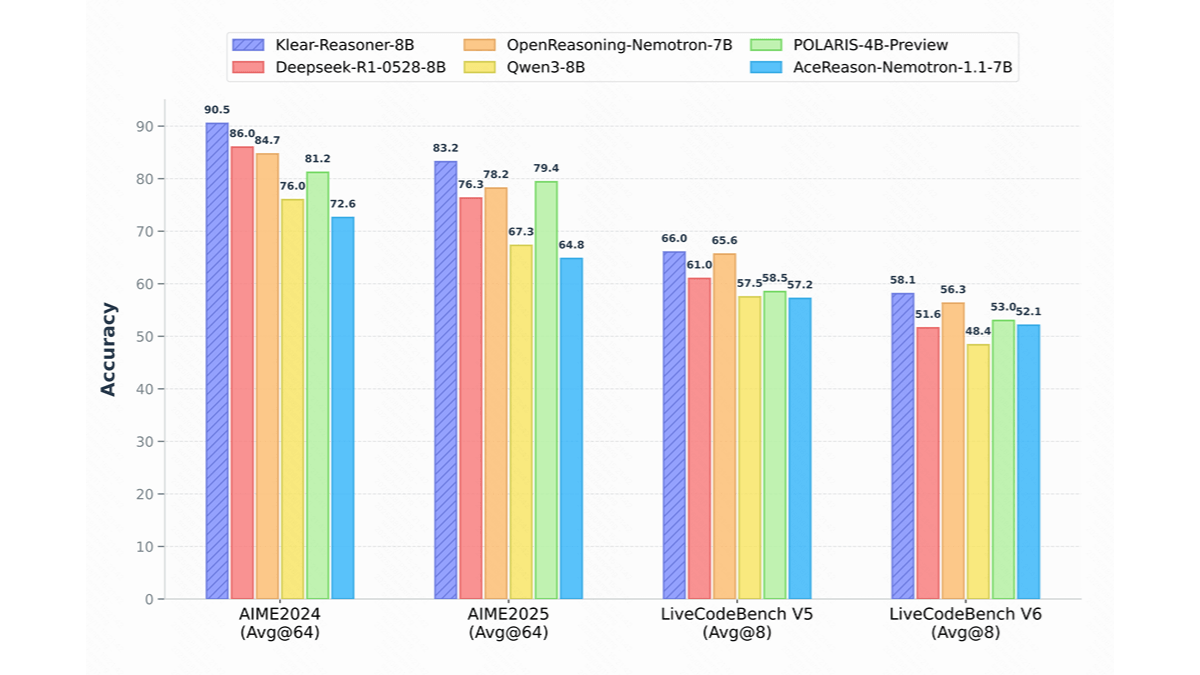
Klear-Reasoner 是快手推出的高性能推理模型,基于 Qwen3-8B-Base 进行开发。模型通过长思维链监督微调和强化学习训练,在数学和代码推理方面表现出色。Klear-Reasoner 的核心创新是 GPPO 算法,基于保留被裁剪的梯度信息,显著提升模型的探索能力和负样本的收敛速度。在 AIME 和 LiveCodeBench 等基准测试中,Klear-Reasoner 展现出卓越的性能,达到 8B 模型的顶尖水平。模型能解决复杂的数学问题,且能生成高质量的代码片段。Klear-Reasoner 广泛应用在教育、软件开发、金融科技等领域,为推理模型的发展提供宝贵的参考和复现路径。