OmniVinci - NVIDIA开源的全模态大语言模型
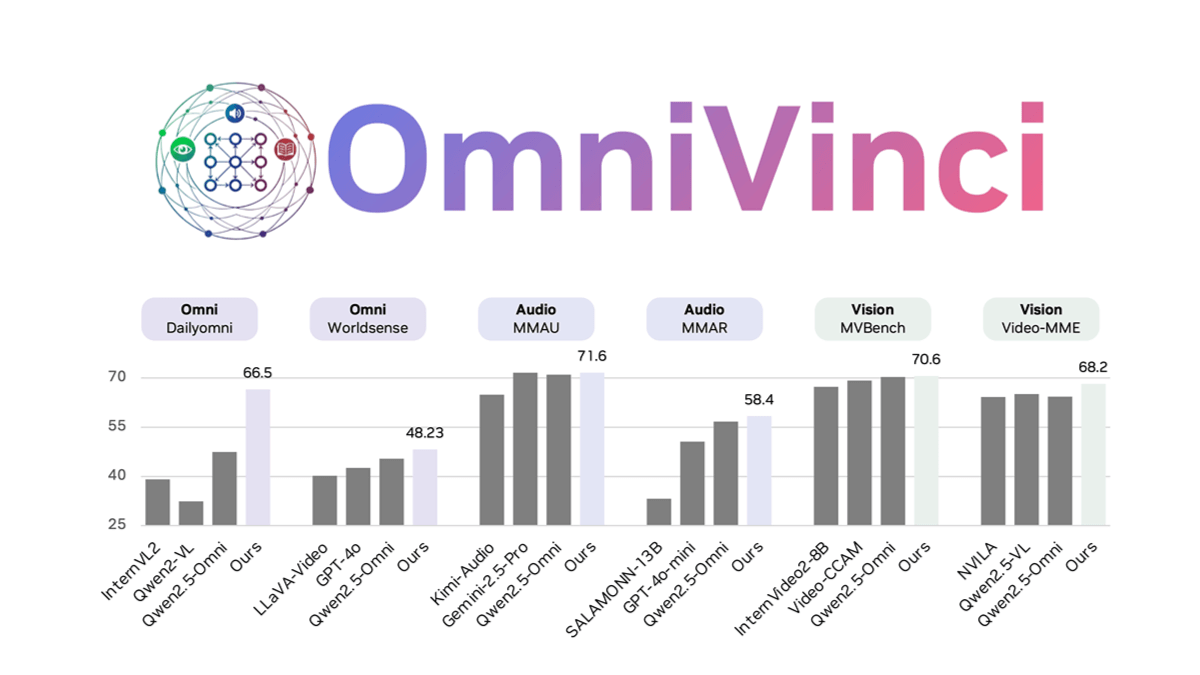
OmniVinci 是 NVIDIA 开发的开源全模态大型语言模型,通过架构革新和数据优化解决多模态模型中的模态割裂问题。通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉相对时间对齐信息,采用约束旋转时间嵌入编码绝对时间信息。OmniVinci 通过数据合成和精心设计的数据分布策略,生成大量单模态和全模态对话样本进行训练。两阶段训练策略先进行单模态训练,再进行全模态联合训练,有效整合多模态理解能力。OmniVinci 在多个基准测试中表现优异,如在 DailyOmni 上评分比 Qwen2.5-Omni 高出 19.05 分,且训练标记量大幅减少。已应用于医疗 CT 影像解读、半导体器件检测等领域,展现出强大的多模态理解能力。