VibeVoice - 微软推出的文本到语音模型
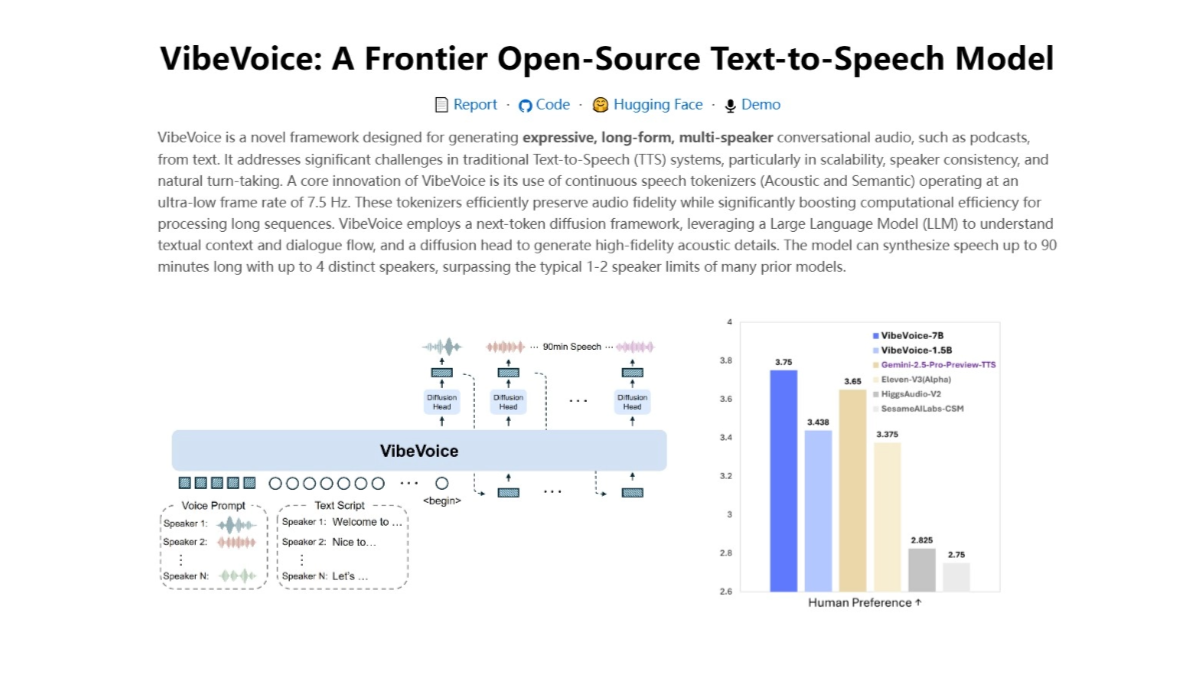
VibeVoice 是微软推出的新型文本到语音(TTS)模型。模型能生成多达 4 位不同说话者的对话式音频,支持长达 90 分钟的连续语音输出,突破传统 TTS 系统的长度限制。VibeVoice 生成的语音富有表现力,能根据文本内容产生带有情感和语调的语音,让对话更自然生动。VibeVoice支持多种语言的语音合成,能处理跨语言对话场景,生成的语音质量高,接近人类自然语音。VibeVoice 能应用在播客制作、有声读物、虚拟助手、教育和培训、娱乐和游戏等多个领域,为相关场景提供自然流畅的语音交互体验。